Can we utilize Large Language Models (LLM) to generate useful linguistic corpora: A case study of the word frequency effect in young German readers
Job Schepens, Nicole Marx, Benjamin Gagl
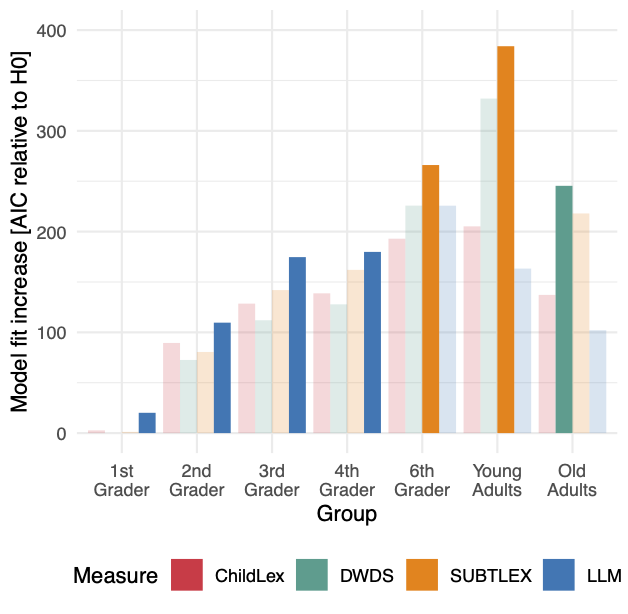
Since only recently, Large Language Models (LLMs) can generate long and coherent stories responding to specific prompts. Here, we utilize LLMs to create a text corpus to estimate word frequency specifically for German-speaking young readers (Grades 1-4). We build the LLM-corpus based on an existing corpus of children's books. We found that the LLM-corpus holds fewer word types but that the frequencies of relatively often occurring words were highly similar. Furthermore, we used the book and LLM-based frequencies to estimate the word frequency effect on reading performance (i.e., faster reading of more frequent words). LLM-based frequencies explained more variance in reading times for readers in Grades 1-4 than the children's book-based frequencies. Therefore, we conclude that LLM-based word frequencies reliably capture the frequency effect on reading performance and outperform conventional frequency estimates in beginning readers. It is thus possible to use LLMs to generate word frequency statistics for specific groups. We discuss these findings, considering the potential risks of using LLMs in this context.
Schepens, Job, Nicole Marx, and Benjamin Gagl. 2023. “Can We Utilize Large Language Models (llms) to Generate Useful Linguistic Corpora? A Case Study of the Word Frequency Effect in Young German Readers.” [Preprint: doi:10.31234/osf.io/gm9b6].